Concepts¶
Architecture¶
Overview¶
Ochopod is a small layer written in Python that is intended to run inside containers (for instance Docker or Rocket). Its primary goal is two fold:
- It provides automatic synchronization amongst multiple containers as well as remote reporting capabilities.
- It runs and manages an underlying process (e.g some web-server, 3rd-party, etc.), restarting it if required.
We leverage this synchronization capability to implement an explicit configuration process where each container is asked to get itself in order while having access to a full, consistent view of the other containers around it. This model is fully automated and just require the user to define the actual configuration logic, typically to render a few files on disk.
Overlay¶
Ochopod is really an overlay that sits on top of a resourcing platform. This overlay hides the internal details specific to Mesos or Kubernetes for instance (typically how pods are identified, where they run, etc) and provides some higher-level model.
Ochopod is meant to be used on top of modern resourcing technologies. Our stack is made of three distinct layers : a pool of resources (either virtualized or bare-metal), the resourcing layer (Kubernetes or Mesos plus one or more frameworks such as Marathon) and finally the application layer on top (e.g Docker and whatever runs in the containers).
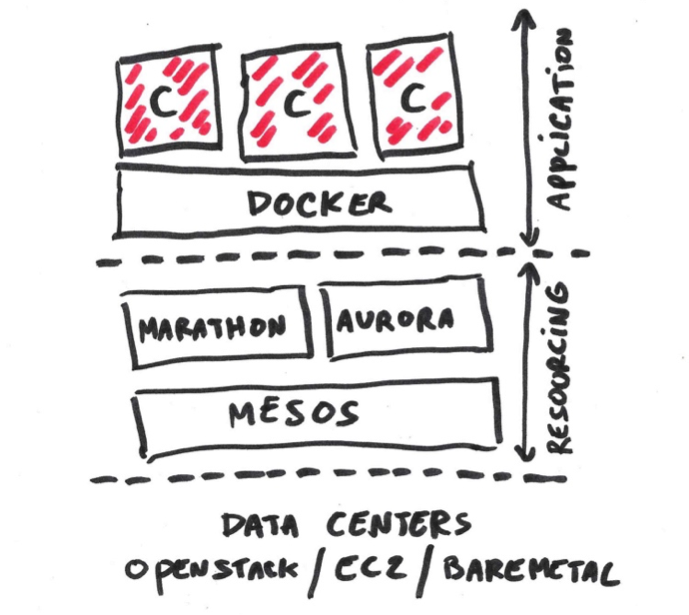
As mentioned above Ochopod runs into containers. From a functional standpoint it acts as a cross between an init and a distributed configuration service (e.g Etcd or Doozer). The catch is that Ochopod will rely on the resourcing layer to store its state depending on what stack is used.
Note
There is no strong constraint around what Zookeeper ensemble is used. For Kubernetes we for instance run a dedicated pod running a standalone Zookeeper. For Marathon we simply piggy back on the internal Zookeeper ensemble used by Mesos.
Ochopod is completely independent from the resourcing layer underneath. The only relationship between the two is the fact the resourcing layer indirectly spawns containers which in turn run Ochopod.
Terminology¶
A container is a self-contained processing unit which is pre-setup with some software (this is for instance accomplished in Docker using a Dockerfile). Container images are immutable and act as a canonical unit for functionality and versioning.
A live container running Ochopod is called a pod. The resourcing layer will run tasks which will spawn one or more such pods. One or more pods running off the same image will form a cluster. If you instantiate your webserver image 3 times you will end up with a 3 pod cluster (not running necessarily on the same resource nor exposing the same ports).
Note
Please note a cluster does not necessarily map to one single Marathon application or Kubernetes replication controller for instance. Clusters are orthogonal to the underlying framework data-model.
Clusters are your basic lego blocks upon which you build more complex distribute systems. Now since the same resource pool may end up running pods sharing a container image in different contexts (consider for instance various deployments of the same service) we assign clusters to a namespace. Clusters within the same namespace can see each others. This semantic is useful to isolate various flavors of the same component (for instance your development and staging pods).
Within a cluster there is always one leader, the rest of the pods being followers.
The pods¶
Layout¶
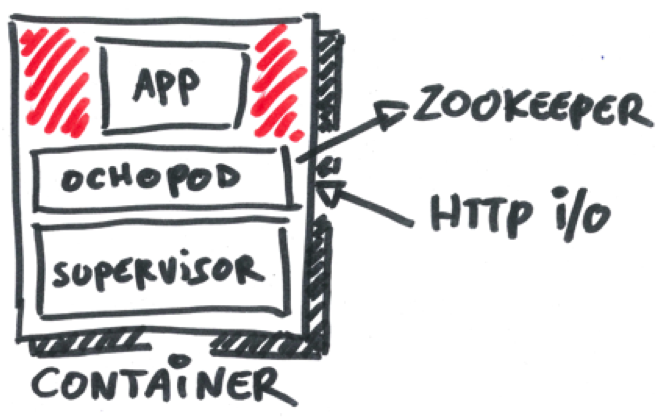
Our pods all follow the same general idea. The Dockerfile defines what bits and pieces should be installed in the container. This includes of course the Ochopod SDK and usually an init system (I like myself to use the cool Supervisord utility). The init system boots and runs a Python script that uses Ochopod. That’s pretty much it.
Synchronization & clustering¶
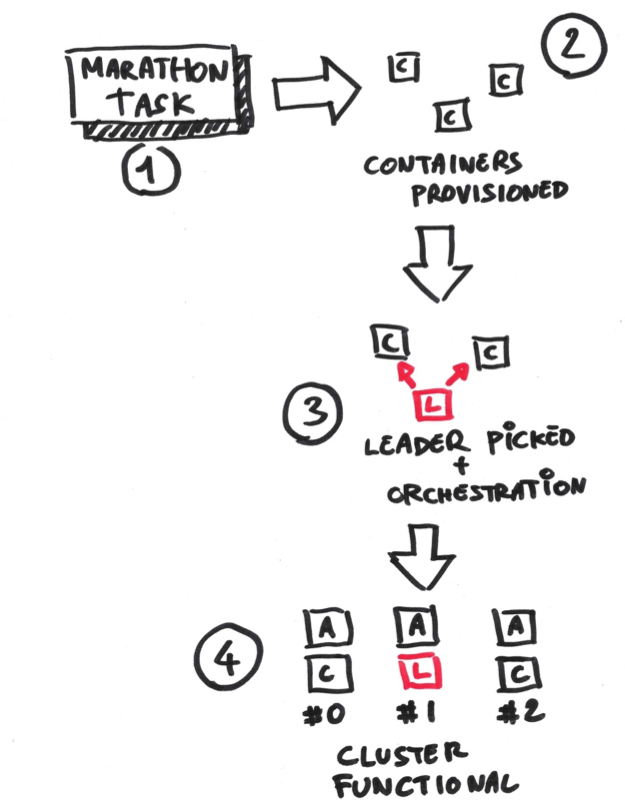
Synchronization is currently performed using Zookeeper. Upon booting each pod will write some information about itself under a node named after the cluster and attempt to grab a lock. The pod obtaining the lock becomes the leader and will start a specific watch process: any modification to the cluster (e.g new pods registering for instance) will trigger a configuration phase.
During the configuration phase the leader requests each pod (including itself) to stop, get setup and run whatever it’s supposed to run. This process is ordered, consistent, sequential or parallel depending on the needs and is coupled with an additional check to make sure it’s okay to go ahead (typically to flag any missing dependency or side-effect). The most important element to remember is that information about all the pods forming the cluster is known at configuration time, which allows us to perform tricky cross-referencing (look at the Zookeeper configuration for a good illustration of what I mean).
Once the configuration phase is successful a hash is persisted. This hash is compounded from all the pods and is used as a mechanism for 3rd parties to tell instantly if any change did occur. If a pod specifies dependencies the same technique applies : any change of a dependency hash will also trigger a re-configuration. This is purely transitive and does not involve any graphing.
Note
A partial and/or transient loss of connectivity between the pods and Zookeeper will result in the leader being notified. To avoid spurious re-configurations of the cluster we use a damper (a configurable time threshold). The hash guarantees we can easily filter situations where one or more pods appear to vanish (connectivity loss) and re-register shortly after.
Note
It may happen we physically lose the leader pod (either that or it is subject to a connectivity loss). In that case another pod in the cluster will obtain the lock and become the new leader. A re-configuration will then be scheduled should the previous leader is gone for good.
Registration¶
When registering to Zookeeper each pod will create a transient node with a unique random id. Its payload is a JSON object whose key/value pairs represent basic information describing stuff such as where the pod runs and what ports they expose.
This data is merged from two sources :
- Environment variables passed by the running framework (Marathon for instance). This is also a way for the user to pass application settings.
- Bindings specific logic, for instance by querying the underlying EC2 instance to grab our current IP.
The important settings are the internal/external IPs used to locate the pod and its port re-mappings (which depend on the stack used). This payload stored in Zookeeper is used and passed down by the leader when configuring the cluster.
Each pod has a unique identifier (UUID) plus a unique index generated from Zookeeper. This index is not guaranteed to span a continuous interval but is indeed unique within the cluster and throughout the lifetime of the pod. Disconnecting and reconnecting to Zookeeper will not affect the UUID nor the index.
HTTP I/O¶
Communication between pods is done via REST/HTTP requests (each pod runs a Flask micro-server listening on a configurable control port). This HTTP endpoint is also used to implement various lookup queries (log, pod information).
All requests return some json payload. HTTP 200 always means success while HTTP 410 indicates the pod has already been killed and is now idling. Soft failures will trigger a HTTP 406.
Each pod can receive the following HTTP requests:
- POST /info: runtime pod information.
- POST /log: current pod log (up to 32KB).
- POST /reset: forces a pod reset and re-connection to Zookeeper.
- POST /control/on: starts the sub-process and potentially configures it.
- POST /control/off: gracefully terminates the sub-process.
- POST /control/ok: triggers the optional post-configuration callback
- POST /control/check: runs a configuration pre-check.
- POST /control/kill: turns the pod off which then switches into idling.
- POST /control/signal: triggers custom user logic.
The POST /info request is meant to provide dynamic information about the pod, typically for 3rd party tools to check whether it is idling or not for instance. The request returns a subset of the settings stored in Zookeeper along with some runtime settings, most importantly process. A value of running means the pod has been configured successfully and is running his sub-process while dead indicates the pod has been terminated and is now idling. For instance:
{
"node": "i-300345df",
"application": "marathon.proxy-2015-03-06-13-40-19",
"task": "marathon.proxy-2015-03-06-13-40-19.c14e769b-c406-11e4-afa0-e9799",
"process": "running",
"ip": "10.181.100.14",
"public": "54.224.203.40",
"status": "",
"ports": {
"8080": 1025,
"9000": 1026
},
"state": "follower",
"port": "8080"
}
The status setting is an arbitrary string that may be set by a leader pod to indicate general information about the cluster.
The POST /control/signal request is a generic placeholder for out-the-band logic. Take for instance the case where you need to switch your web-tier into a special mode or maybe update your load-balancer configuration on the fly. This can be neatly packaged in your pod script and activated using a single HTTP request.
The state-machine¶
Upon startup the pod will idle until it receives a POST /control/on request from its leader at which point it will configure itself. When the configuration succeeds the pod will fork whatever process it’s told to. This sub-process will then be monitored and restarted if it exits on a non zero code. Any further configuration request will first gracefully terminate the sub-process before re-forking it.
Note
You can also define custom logic to handle the sub-process health-check and tear down. The default tear down is implemented by sending a SIGTERM and waiting for the sub-process to terminate (for up to a minute).
Note
You can specify a configuration sequence in which all pods get started sequentially if needed. By default they will be started in parallel.
Upon fatal failures the pod will gracefully slip into a dead state but will still be reachable (for instance to grab its logs). Additional requests are also supported to manually restart the sub-process or turn it on/off. During re-configuration any pod tagged as dead will be skipped silently and therefore not seen by its peers.
Assessing health¶
We propose two ways to gauge whether or not the system behaves as expected : an optional sanity check run by each pod and focusing on the process it manages and an optional probe that is run by the leader pod only and is meant to check on the whole cluster.
Both checks are implemented as callbacks and can be run at varying frequency. The sanity check focuses on what the pod actually runs (e.g its sub-process) and can be customized any way you want (CURL the process, run a script, read some file, etc). Failure to run the sanity checks up to a configurable amount of retries will automatically turn the pod off (up to the user to turn it back on).
Note
Any unexpected exit of the sub-process (e.g anything other than zero) will automatically fail the next sanity check.
Framework bindings¶
Each framework has specific ways to convey settings to its tasks. The SDK offers bindings (e.g entry points) which will know how to read those settings and start the pod. The contract between the pod and the framework is minimal and revolves mostly around getting the pod the data it needs.
Ochopod does not define any data-model of its own to manage pods, version them, perform rolling deployments, etc. This is typically built on top by defining custom tools and taking advantage of each framework capabilities. For instance Marathon offers enough semantics with its application REST API to implement a simple CI/CD pipeline.
Our pods transport 2 dedicated hints : application and task. The application identifies the high-level construct through which the pod was created (for instance a replication controller in the Kubernetes case). The task identifies the pod itself in the underlying stack. Those concepts should not really matter for you and are only relevant to the tooling infrastructure interfacing with Kubernetes or Marathon.
Note
We only offer bindings to run over Kubernetes and Marathon over AWS EC2 at this point.